Azure Data Bricks: Overview


Share

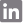


What is Azure Databricks?
Azure Databricks is Apache spark based big data and analytics platform optimized for Azure cloud services. Databricks includes an interactive notebook environment, monitoring tools and security controls that make it easy to leverage Spark. Azure Databricks supports multiple languages such as Scala, Python, R and SQL. Along with these it supports multiple API’s. Azure Databricks offer three environments for developing data intensive applications:
- Databricks SQL
- Databricks Data Science & Engineering
- Databricks Machine Learning
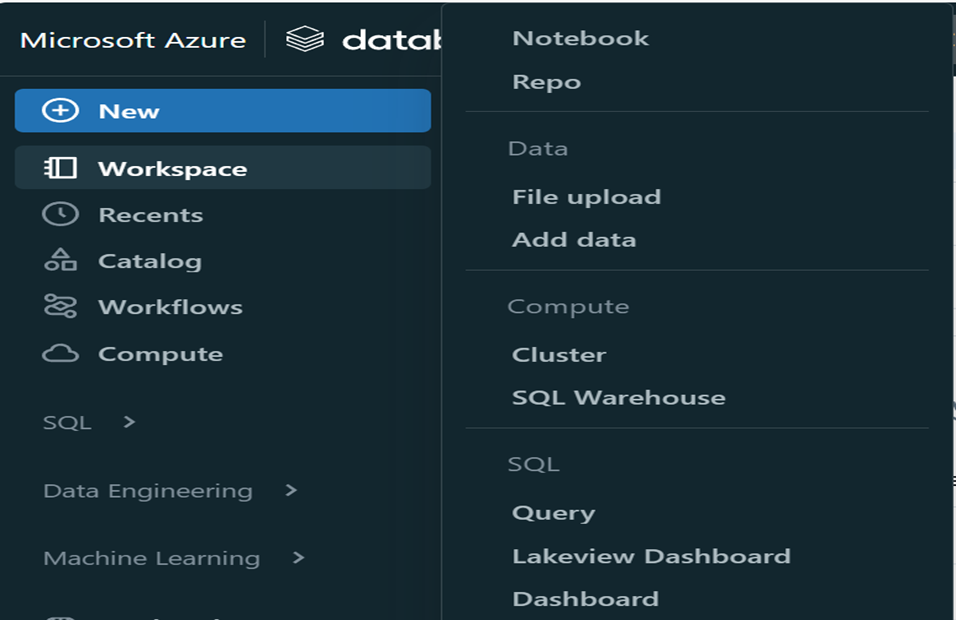
Fig. Azure Environment
Azure Databricks empowers organizations to extract meaningful insights from their data, whether through interactive analysis, batch processing, or machine learning, and is a key component in Microsoft’s Azure analytics and data services ecosystem.
How do Databricks work in Azure?
Azure databricks is optimized for Azure and highly integrated with other azure services like Data Lake Storage, Azure Data Factory and Power BI to store all data in simple open lakehouse. On top of this Azure Databricks integrates seamlessly with Azure Active Directory for access control and authentication. Overall azure databricks provides well architected and tightly integrated environment for big data analytics and machine learning on Azure.
Components of Azure Databricks:
The key components of the Azure Databricks platform include:
- Workspace
- Notebooks
- Clusters
- Workflows
- Delta Lake
- Auto Loader
Workspace: Azure Databricks Workspace is an integrated development environment (IDE) provided by Microsoft Azure for data engineering, data science, and machine learning tasks. It’s a collaborative platform that allows multiple users to work together on big data analytics. We can write code and configure jobs using workspace.
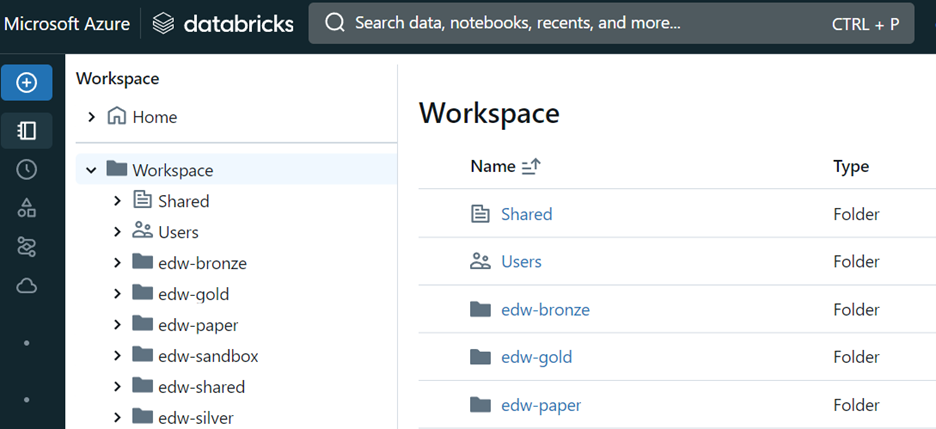
Fig. Azure workspace
Notebooks: Azure Databricks provides a notebook interface where users can write and execute code in multiple languages, such as Python, Scala, SQL, and R. Notebooks are interactive documents that combine live code, visualizations, and narrative text, making it easy to explore, analyze, and visualize data. Any type of business logic we can write and apply on data using notebooks.
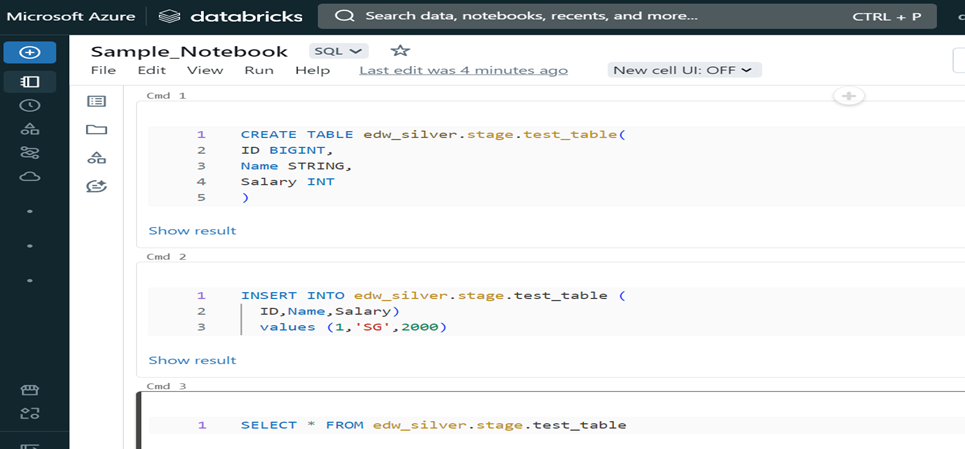
Fig. Sample Notebook
Clusters: A databricks cluster is a set of computation resources and configurations on which you run data engineering, data science and data analytics workloads. These workloads such as ETL pipelines, streaming analytics, ad hoc analytics are run as a set of commands in notebook or as a Job. There are primarily two types of clusters, All-purpose clusters and Job clusters. All-purpose clusters analyze data collaboratively using interactive notebooks, while job clusters run automated jobs in an expeditious and robust way. It’s better to use All-purpose clusters for ad hoc requests and development work. Cluster’s usually takes 3 to 6 minutes to start, and we can stop it manually or it is auto terminated after certain set limit. Also, there is SQL warehouse compute available for ad hoc SQL queries which takes relatively less time to start.

Fig. Cluster’s
Delta Lake: Delta Lake is the technology at the heart of Azure Databricks platform. It is open-source technology that enables building a data Lakehouse on top of existing storage systems. Delta Lake builds upon standard data formats, it is primarily powered by data stored in the parquet format, one of the most popular open-source formats for working with big data. Additionally, Delta Lake is default for all tables created in Azure Databricks.
Data Bricks Auto Loader: Auto Loader provides an easy-to-use mechanism for incrementally and efficiently processing new data files as they arrive in cloud file storage. This optimized solution provides a way for data teams to load raw data from cloud object stores at lower cost and latency. By using Auto loader no tuning or manual code required. Auto loader can load files from ADLS Gen2, Azure Blob Storage and Data Bricks File System. Auto loader can be very useful and efficient when used with Delta Live Tables.
Workflows: A workflow is a way to run non interactive code in databricks clusters. For example, you can run ETL workload interactively or on a schedule. A workflow can consist of a single task or can be a large, multitask workflow with complex dependencies. Azure Databricks manages the task orchestration, cluster management, monitoring and error reporting for all the jobs. We can run jobs immediately or periodically through an easy-to-use scheduling system. Also, we can set dependency on upstream job by using file arrival trigger in workflow.
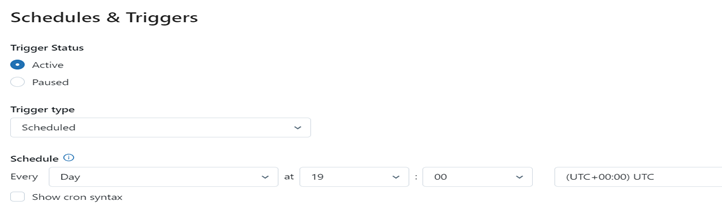
Fig. Workflow Schedule and Triggers
Summary: Azure Databricks can be very useful and game changer in today’s modern big data analysis due to its optimized environment, Persistent collaboration in notebooks, real time team-work and user-friendly workspace. Also, azure databricks integrates closely with PowerBI for hand-on visualization, this can be very effective for ad hoc analysis.
For more updates like this, please get in touch with us.
Ready to get started?
From global engineering and IT departments to solo data analysts, DataTheta has solutions for every team.