Client Story
Data Lake and cognitive search program for a Life Science enterprise

Share




Business Problem
The biology, chemistry, clinical, and regulatory teams of our life science client form a formidable part of their business operations. These teams engage in experimental research, collecting the experimental data in various forms such as numerical values, images, genomic sequences, clinical outcome-related data, regulatory information about their research, patient health information, and more. These data form the central element of the business success of the customer. This data are stored in an unorganized manner that takes at least 2 – 6 weeks for the knowledge workers to discover the data from a data swamp or sometimes even lost. In this environment, the right information is hard to find that derails the productivity thereby the time to market. DataTheta created a smart and natural language processing based system to retrieve the information just-in-time.
Data Solution
The data solution conceived by DataTheta has the following the building blocks on the cloud platform:
- Data Ingestion: Tools and services that enables to orchestrate the data from disparate locations/sources.
- Data Store: Unified, yet composite data storage location for further processing of the data and files.
- Data Catalog: System that helps to understand the data movement and lineages of data from various stages of the data flow.
- Cognitive Search: An intelligent program or service that understands the natural language and retrieves the information as per the search queries.
- Compliance Packs: A data governance frame work that logs the identity and changes made on the document and presents as per the regulatory and compliance needs (21 CFR Part 11 of USFDA) to the end user.
Above data solution in implemented to meet the business objectives.
Above data solution in implemented to meet the business objectives.
Implementation
The below architecture is implemented to meet the business objectives:
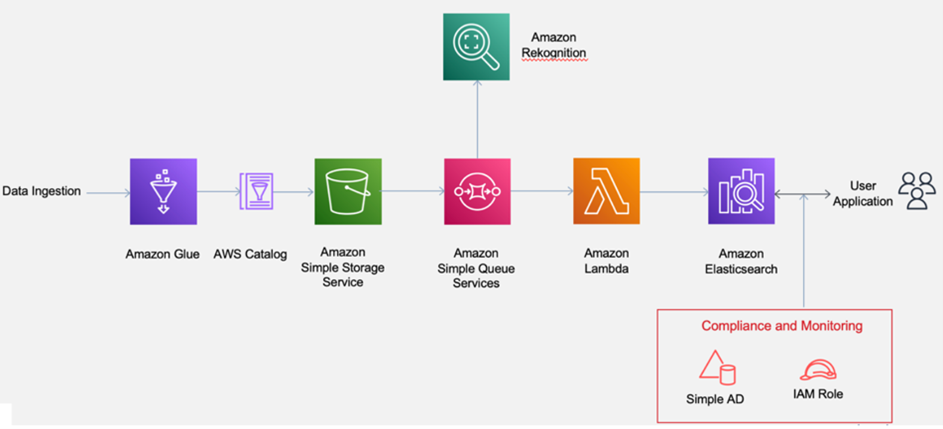
The data sources were the office productivity tools and the CRO resources. A fine-grained compliance pack was implemented to incorporate the access policy and governance. Amazon recognition clusters were deployed to index the data and the NLP model was trained to provide contextual search experience to the users.
KPI
Contextual data retrieval
Duration
20 Weeks
End user
Research Scientists
Business Group
Scientific Operations
Tools Used
Value Creation
Data Governance is an important aspect of the Life Science industry projects. This project was implemented within the guardrails of 21 CFR Part 11 regulations. The scientific operations teams were able to perform a contextual and deep search on the documents stored in the office productivity software and the CRO locations. This enabled a seamless flow of information assimilation for business success.
Ready to get started?
From global engineering and IT departments to solo data analysts, DataTheta has solutions for every team.