
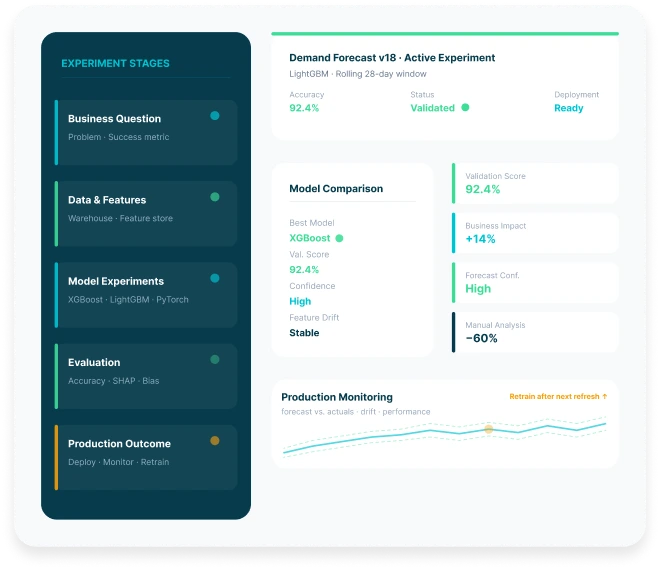



A senior data scientist embedded in your team owns the analysis, models, experiments, validation and decision intelligence needed to turn complex data into measurable business outcomes.

Build forecasting, classification, scoring, and regression models that help teams predict demand, risk, churn, performance and operational outcomes.
Python, scikit-learn, XGBoost, LightGBM

Design A/B tests, uplift models, causal studies and measurement frameworks that separate signal from noise.
Statsmodels, DoWhy, CausalML, Optimizely

Develop reproducible training, validation, feature engineering, model evaluation and deployment workflows for production-ready machine learning.
MLflow, Kubeflow, Feast, Airflow

Segment customers, analyze journeys, predict lifetime value, identify churn risk and uncover patterns that improve growth decisions.
pandas, SQL, Amplitude, Mixpanel

Create demand forecasts, capacity models, pricing simulations, inventory optimization and planning models for better operational decisions.
Prophet, Nixtla, OR-Tools, PyMC

Track model performance, drift, explainability, bias, documentation and review workflows so teams can trust decisions over time.
Evidently, WhyLabs, SHAP, Great Expectations
To contributing
Dedicated to your team
Minimum engagement
Typical match time
DataTheta team behind them
Production experience
Sprint planning

Analysis build

Modeling

Collaboration

Ops and handover
Data Scientist II
3–5 years · Supervised delivery
Best for defined analysis, model development, experiments and supporting a senior lead. Strong execution focus.
Senior Data Scientist
5–9 years · Independent ownership
Owns analysis, models and experiments end to end. Makes methodology decisions, explains tradeoffs, and drives measurable outcomes without needing hand-holding.
Principal / Staff Data Scientist
9+ years · Platform leadership
Sets technical direction for advanced analytics and machine learning. Best for high-impact modeling, causal strategy, AI roadmap design, or teams needing a technical anchor.

Tell us the stack and the gap
Share the business objective, data context and what they need to own. A 30-minute conversation, no forms.

We propose within 5 days
A named scientist from our bench, with background, experience and a short technical assessment relevant to your problem.

You decide
A technical interview runs your way. If the fit is not right, we rematch at no cost. No commitment until you say yes.

In your team by week two
Structured onboarding, committed modeling work and standups from week two.
See how embedded engineering capability improves pipelines, platforms, quality, and decision speed.

Embedded data engineering support helped unify POS, inventory, and promotion data into reliable pipelines for demand forecasting and planning.
34% forecast accuracy improvement
A governed data platform connected claims, provider, clinical, and member data to support reporting, risk scoring, and operational analytics.
3 weeks to 2 days reporting prep
Event-driven pipelines brought sensor and operational data together to support asset monitoring and early risk detection.
14-day advance failure prediction
Answers to common questions about embedding a senior data scientist through DataTheta.
We usually propose a suitable data scientist within 5 working days. After alignment, onboarding is structured so they can contribute meaningfully by week two.
Yes. The scientist is embedded into your team, standups, tools and delivery rhythm. They work as a dedicated contributor, not a disconnected external resource.
Yes. DataTheta matches scientists based on your current warehouse, notebooks, BI, ML, experimentation and MLOps stack. The goal is fast contribution without forcing unnecessary platform changes.
We rematch quickly if the scientist is not the right fit for your technical needs, stakeholder style, team culture or delivery expectations. You should only continue when the match works.
Yes. Engagements can extend into long-term embedded support, model ownership, experimentation leadership, or expanded data science capacity. Many clients start with one scientist and scale once value is proven.
Problem, data, team size, duration — give us the context. We’ll have a name for you within five working days.
Build reliable pipelines, data platforms, transformations and observability practices that make enterprise data production-ready.
Build and operate the cloud, infrastructure, DevOps and platform foundations your data and AI teams need to ship reliably.
Create trusted models, metrics layers, dashboards and documentation so business teams can make decisions from reliable data.

DataTheta is an enterprise Data, Analytics, and AI consulting company that helps organizations build AI-ready data foundations through Data Engineering, Data Science, Business Intelligence, Data Warehousing, Generative AI, and On-Demand Experts.
© 2026 DataTheta